01. NLP 처리란?
- Natural Language (자연어) : 일상 생활에서 사용하는 언어
- Natural Language Processing (자연어 처리) : 일상 생활 언어를 컴퓨터가 처리할 수 있도록 하는 가공 작업
- NLP 예시 ... 음성 인식, 번역, 감성 분석, 텍스트 분류, 챗봇
- NLP 모델 ... 뒷 파트에서 서술
01-01. 아나콘다/코랩 환경 세팅
- 파이썬 배포판 아나콘다 설치 진행 ... 아래 페이지에서 적당한 버전으로 설치
https://repo.anaconda.com/archive/ - 아나콘다 프롬프트 실행 및 파이썬 패키지 최신 버전 업데이트
> conda update -n base conda
...
done
> conda update --all
...
Retrieving notices: ...working... done
- 구글 코랩 환경 설정
런타임 -> 런타임 유형 변경 : GPU로 변경
01-02. 프레임워크 및 라이브러리 설치
- 아나콘다 설치 시 Numpy, Pandas, Jupyter notebook, matplotlib 등이 설치되지만,
tensorflow, keras 등은 별도 pip를 통해 설치 필요
1) Tensorflow
- 머신러닝 오픈소스 라이브러리
- 아나콘다 프롬프트에 커맨드 입력
> pip install tensorflow
- ipython 쉘에 텐서플로우 임포트
In [1]: import tensorflow as tf
In [2]: tf.__version__
Out[2]: '2.11.0'
2) Keras
- 텐서플로우의 백엔드로서 더 간단한 코드를 작성할 수 있게하는 라이브러리
(텐서플로우에서 케라스 API를 사용하는 경우 보통 tf.keras로 표기)
# anaconda prompt
> pip install keras
# ipython
In [3]: import keras
In [4]: keras.__version__
Out[4]: '2.11.0'
3) Gensim
- 머신러닝을 사용해 토픽 모델링 및 자연어 처리를 수행하게 해주는 오픈소스 라이브러리
# anaconda prompt
> pip install gensim
...
Successfully installed Cython~
# ipython
In [5]: import gensim
In [6]: gensim.__version__
Out[6]: '4.2.0'
4) Scikit-learn
- 파이썬 머신러닝 라이브러리
나이브 베이즈 분류, 서포트 벡터 머신 등의 모듈을 불러올 수 있음
아나콘다로 자동 설치됨
# ipython
In [7]: import sklearn
In [8]: sklearn.__version__
Out[8]: '0.24.1'
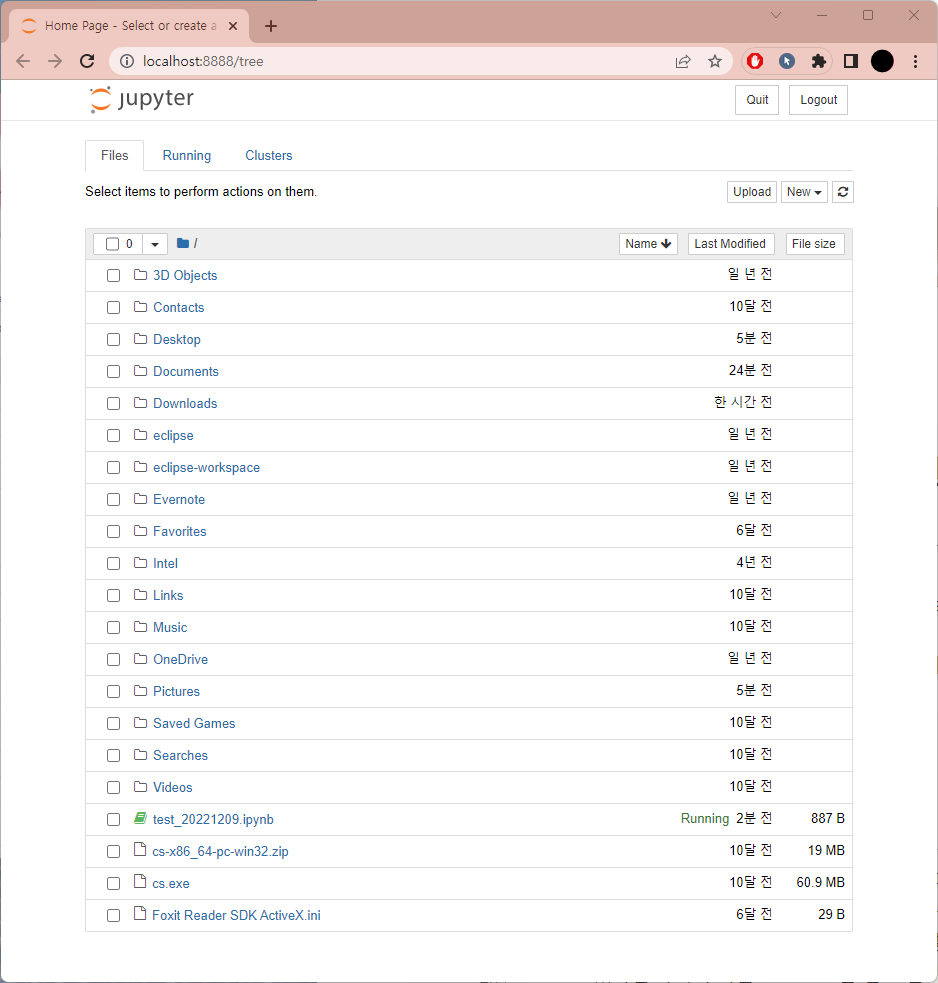
5) Jupyter Notebook
- 웹에서 코드를 작성하고 실행할 수 있는 오픈소스 웹 어플리케이션
아나콘다로 자동 설치됨 - 실행 방법 : 아나콘다 프롬프트에서 jupyter notebook 입력
또는 웹 브라우저에 localhost:8888 입력
01-03. NLTK, KoNLPy 설치
- 텍스트 전처리 실습을 위한 기본적인 자연어 패키지 설치
1) NLTK, NLTK Data 설치
- NLTK : 자연어 처리를 위한 파이썬 패키지
아나콘다로 자동 설치됨
# ipython
In [9]: import nltk
In [10]: nltk.__version__
Out[10]: '3.6.1'
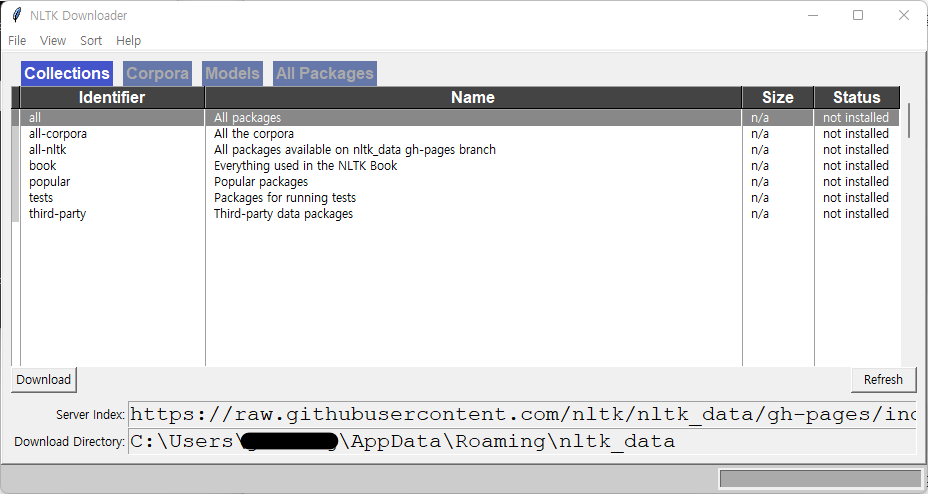
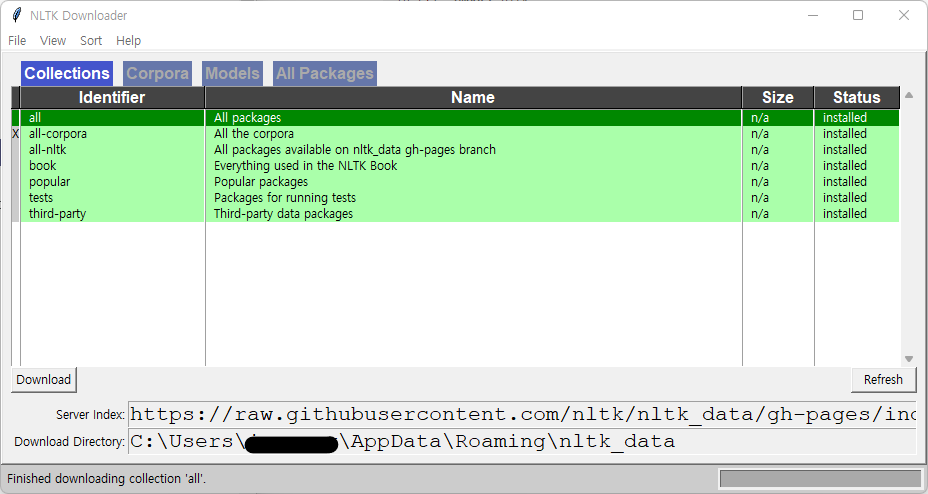
2) KoNLPy 설치
- KoNLPy : 한국어 자연어 처리를 위한 형태소 분석기 패키지
# anaconda prompt
> pip install konlpy
...
Successfully installed JPype1-1.4.1 konlpy-0.6.0
# ipython
In [12]: import konlpy
In [13]: konlpy.__version__
Out[13]: '0.6.0'
01-04. Pandas, Numpy, Matplotlib
- Pandas, Numpy, Matplotlib 모두 아나콘다로 자동 설치됨
1) Pandas
- 파이썬 데이터 처리를 위한 라이브러리
보통 pd라는 명칭으로 임포트 - 3가지의 데이터 구조 사용
# ipython
In [1]: import pandas as pd
In [2]: pd.__version__
Out[2]: '1.2.4'
(1) Series
- 1차원 배열값(values)에 대응되는 인덱스(index)를 부여하는 구조를 가짐
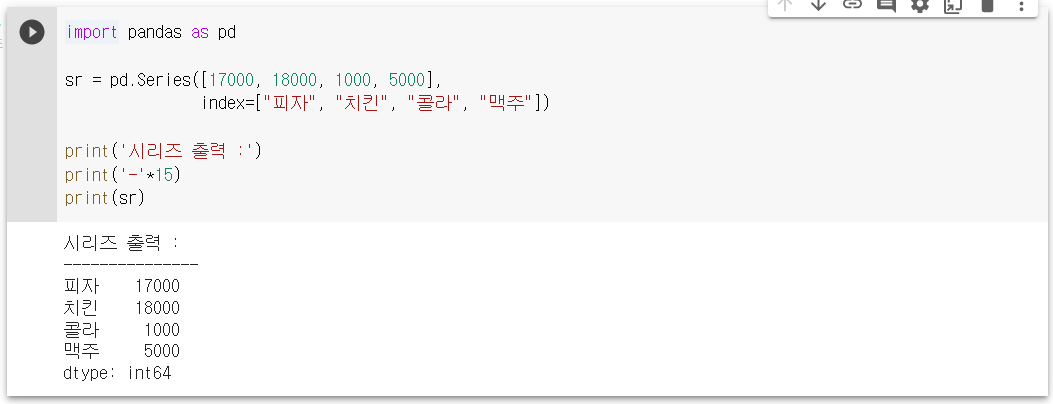
import pandas as pd
sr = pd.Series([17000, 18000, 1000, 5000],
index=["피자", "치킨", "콜라", "맥주"])
print('시리즈 출력 :')
print('-'*15)
print(sr)
시리즈 출력 :
---------------
피자 17000
치킨 18000
콜라 1000
맥주 5000
dtype: int64
print('시리즈의 값 : {}'.format(sr.values))
print('시리즈의 인덱스 : {}'.format(sr.index))
시리즈의 값 : [17000 18000 1000 5000]
시리즈의 인덱스 : Index(['피자', '치킨', '콜라', '맥주'], dtype='object')

(2) Dataframe
- 행과 열을 가지는 2차원 자료구조
- 열(columns), 인덱스(index), 값(values)로 구성
values = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
index = ['one', 'two', 'three']
columns = ['A', 'B', 'C']
df = pd.DataFrame(values, index=index, columns=columns)
print('데이터프레임 출력 :')
print('-'*18)
print(df)데이터프레임 출력 :
------------------
A B C
one 1 2 3
two 4 5 6
three 7 8 9
print('데이터프레임의 인덱스 : {}'.format(df.index))
print('데이터프레임의 열이름: {}'.format(df.columns))
print('데이터프레임의 값 :')
print('-'*18)
print(df.values)
데이터프레임의 인덱스 : Index(['one', 'two', 'three'], dtype='object')
데이터프레임의 열이름: Index(['A', 'B', 'C'], dtype='object')
데이터프레임의 값 :
------------------
[[1 2 3]
[4 5 6]
[7 8 9]]
- 데이터프레임 생성 : 리스트, 시리즈, 딕셔너리, ndarrys, 데이터프레임으로부터 생성 가능
# 딕셔너리로 생성
data = {
'학번' : ['1000', '1001', '1002', '1003', '1004', '1005'],
'이름' : [ 'Steve', 'James', 'Doyeon', 'Jane', 'Pilwoong', 'Tony'],
'점수': [90.72, 78.09, 98.43, 64.19, 81.30, 99.14]
}
df = pd.DataFrame(data)
print(df)
학번 이름 점수
0 1000 Steve 90.72
1 1001 James 78.09
2 1002 Doyeon 98.43
3 1003 Jane 64.19
4 1004 Pilwoong 81.30
5 1005 Tony 99.14
- 데이터프레임 조회
-- df.head(n) : 앞에서 n개만 조회
-- df.tail(n) : 뒤에서 n개만 조회
-- df['열이름'] : 해당되는 열 조회
- 외부 데이터 읽기 : Pandas에서는 CSV, 텍스트, 엑셀, SQL, HTML, JSON 등의 파일을 읽어와 데이터프레임 생성 가능
# csv 파일 읽어오기
df = pd.read_csv('example.csv')
2) Numpy
- 수치 데이터를 다루는 파이썬 패키지
다차원 행렬 자료구조인 ndarray를 통한 선형대수 계산에서 주로 사용
보통 np라는 명칭으로 임포트
# ipython
In [3]: import numpy as np
In [4]: np.__version__
Out[4]: '1.20.1'
(1) np.array()
- 리스트, 튜플, 배열로부터 ndarray 생성
import numpy as np
# 1차원 배열
vec = np.array([1, 2, 3, 4, 5])
print(vec)
[1 2 3 4 5]
# 2차원 배열
mat = np.array([[10, 20, 30], [ 60, 70, 80]])
print(mat)
[[10 20 30]
[60 70 80]]
- vec과 mat 배열 비교
print('vec의 타입 :',type(vec))
print('mat의 타입 :',type(mat))
vec의 타입 : <class 'numpy.ndarray'>
mat의 타입 : <class 'numpy.ndarray'>
-> numpy.ndarray로 동일한 타입으로 출력
축의 개수(ndim)와 크기(shape)로 배열의 크기 계산 -> ★중요★
print('vec의 축의 개수 :',vec.ndim) # 축의 개수 출력
print('vec의 크기(shape) :',vec.shape) # 크기 출력
print('mat의 축의 개수 :',mat.ndim) # 축의 개수 출력
print('mat의 크기(shape) :',mat.shape) # 크기 출력vec의 축의 개수 : 1
vec의 크기(shape) : (5,)
mat의 축의 개수 : 2
mat의 크기(shape) : (2, 3)
3) Matplotlib
- 데이터를 차트나 플롯으로 시각화하는 패키지
보통 mpl라는 명칭으로 임포트
주요 모듈인 pyplot을 보통 plt라는 명칭으로 임포트
# ipython
In [1]: import matplotlib as mpl
In [2]: mpl.__version__
Out[2]: '3.3.4'
import matplotlib.pyplot as plt
# 라인 플롯 그리기
plt.title('test')
plt.plot([1,2,3,4],[2,4,8,6])
plt.show()
# 축 레이블 삽입
plt.title('test')
plt.plot([1,2,3,4],[2,4,8,6])
plt.xlabel('hours')
plt.ylabel('score')
plt.show()
# 라인 추가 및 범례 삽입
plt.title('students')
plt.plot([1,2,3,4],[2,4,8,6])
plt.plot([1.5,2.5,3.5,4.5],[3,5,8,10]) # 라인 새로 추가
plt.xlabel('hours')
plt.ylabel('score')
plt.legend(['A student', 'B student']) # 범례 삽입
plt.show()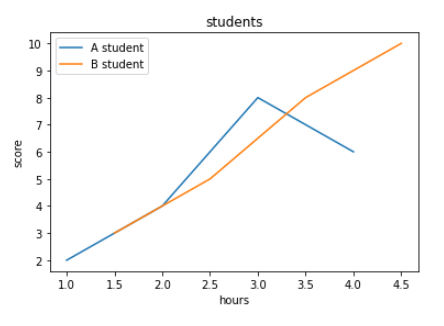
01-05. 판다스 프로파일링
- 좋은 머신러닝 결과를 얻기 위해서는 데이터의 성격을 파악하는 과정이 선행되어야 함
- EDA(Exploratory Data Analysis) : 탐색적 데이터 분석 - 데이터 분포, 변수 간 관계, 결측값 유무 확인 등의 파악 과정
# anaconda prompt
> pip install -U pandas-profiling
...
Successfully installed htmlmin-0.1.12~
★ pandas-profiling은 여러 라이브러리 버전에 의존적이므로,
2.8.0 버전으로 사용하는 것을 추천함.
(https://www.inflearn.com/questions/334386/pandas-profiling-version-%EC%98%A4%EB%A5%98%EC%99%80-profiling-report%EB%A5%BC-htlm-%ED%8C%8C%EC%9D%BC-%ED%98%95%EC%8B%9D%EC%9C%BC%EB%A1%9C-%EC%A0%80%EC%9E%A5%ED%95%98%EB%8A%94%EB%8D%B0-%EC%98%A4%EB%A5%98)
- 실습 파일 다운 및 불러오기
아래 URL에서 spam.csv 다운
https://www.kaggle.com/uciml/sms-spam-collection-dataset
코랩에 파일 업로드 및 불러오기
import pandas as pd
import pandas_profiling
data = pd.read_csv('spam.csv',encoding='latin1')
data[:5]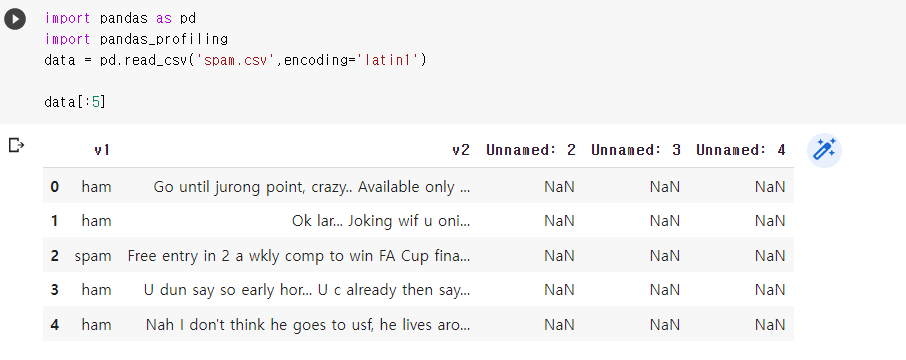
- 리포트 생성 및 살펴보기
pr=data.profile_report() # 프로파일링 결과 리포트를 pr에 저장
pr # pr에 저장했던 리포트 출력
<br>
## 01-06. 머신러닝 워크플로우
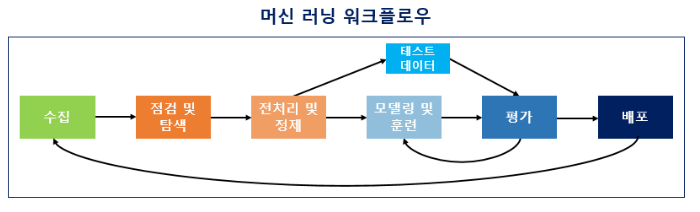
#### 1) 수집 (Acquisition)
말뭉치 = 코퍼스(corpus) : 학습 데이터로서 사용하기 위한 특정 도메인으로부터 수집된 텍스트 집합
<br>
#### 2) 점검 및 탐색 (Inspection and exploration)
EDA 단계 : 독립/종속 변수 및 변수의 데이터 타입 등을 점검하며 데이터의 특징과 구조적 관계를 알아내는 과정
<br>
#### 3) 전처리 및 정제 (Preprocessing and Cleaning)
토큰화, 정제, 정규화, 불용어 제거 등의 단계를 통해 데이터 전처리 진행
<br>
#### 4) 모델링 및 훈련 (Modeling and Training)
적절한 머신러닝 알고리즘을 선택하여 모델링이 끝났다면, 전처리가 완료된 데이터를 머신러닝 알고리즘을 통해 기계에 학습시킴 (훈련)
기계가 데이터에 대한 학습을 마쳤다면 자연어 처리 작업을 수행
<br>
**★ 과적합(Overfitting) 방지**
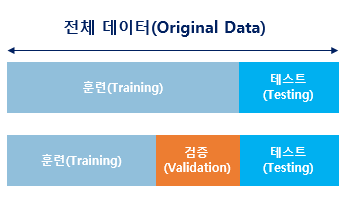
전체 데이터 중 일부 데이터는 검증(테스트)용으로 남겨두어야 추후 테스트 데이터를 통해 성능 측정 및 과적합* 방지가 가능함.
* 과적합 (Overfitting) : 학습데이터를 과하게 학습하여 학습데이터에 대해서는 오차가 감소하지만 실제데이터에 대해서는 오차가 증가하게 되는 것
- 훈련용 : 학습지
- 검증용 : 모의고사
- 테스트용 : 수능시험
<br>
#### 5) 평가 (Evaluation)
학습이 완료되면 테스트용 데이터로 성능 평가
<br>
#### 6) 배포 (Deployment)
평가 단계에서 기계가 성공적으로 훈련이 된 것으로 판단된다면 완성 모델을 배포
<br>
<br>
<br>
참고문서 : 딥러닝을 이용한 자연어 처리 입문 ([https://wikidocs.net/book/2155](https://wikidocs.net/book/2155))
https://ko.wikipedia.org/wiki/%EA%B3%BC%EC%A0%81%ED%95%A9
